ReLU Networks
Date: March 13, 2026 | Author: Roland Gao
In the past few weeks, I've been thinking increasingly about basic neural networks, such as one composed of linear and ReLU layers.
It's hard to understand what exactly the network is doing, or why it works. A network with only linear and ReLU layers seems very constrained in its capacity, yet the Universal Approximation Theorem says that a 2-layer network can approximate any function arbitrarily well given enough neurons in the hidden layer.
To resolve this conflict in my understanding of neural networks, I went on a journey to understand them a bit more.
ReLU networks can sort the input
Sorting is a highly nonlinear function, but it's possible for a neural network to sort the input.
When there are only two numbers in the input, we can compute the max as follows:
If a is larger than b, then .
If b is larger than a, then .
We can compute the min as:
By computing the min and the max, we essentially sorted the input with two numbers.
We can easily extend this to 3 dims, where we use to compute the max, to compute the min, and .
In general, such a network is called a sorting network. We can naively use a algorithm such as bubble sort, where we find the max among all elements, and then find the max among the remaining elements, and so on. There are also specialized algorithms such as bitonic sort, with runtime complexity.
ReLU networks can produce common shapes
We've seen how ReLU can be used to compute , but how about ? We can chain two ReLUs, but we can also use two ReLUs in parallel as follows:
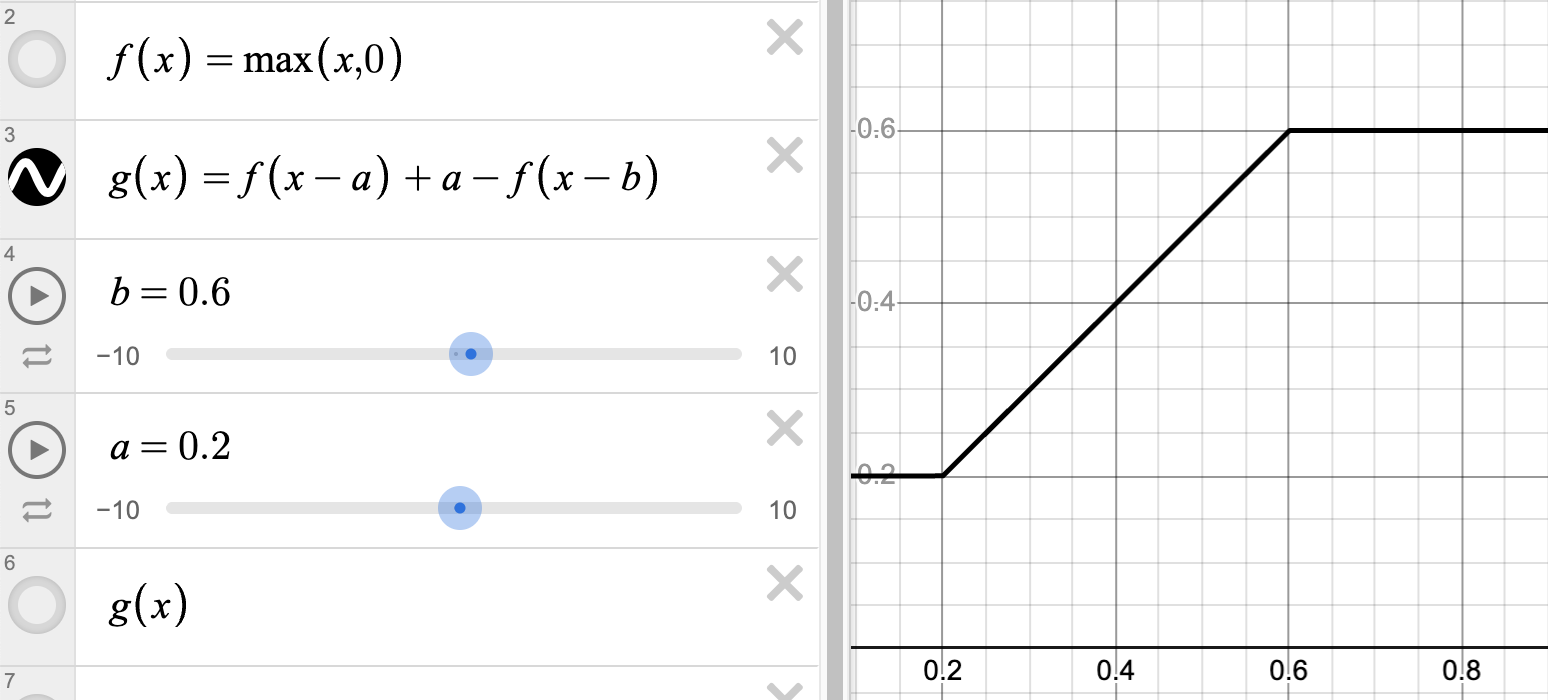
With two clip functions in parallel, we can create shapes like buckets and triangles.
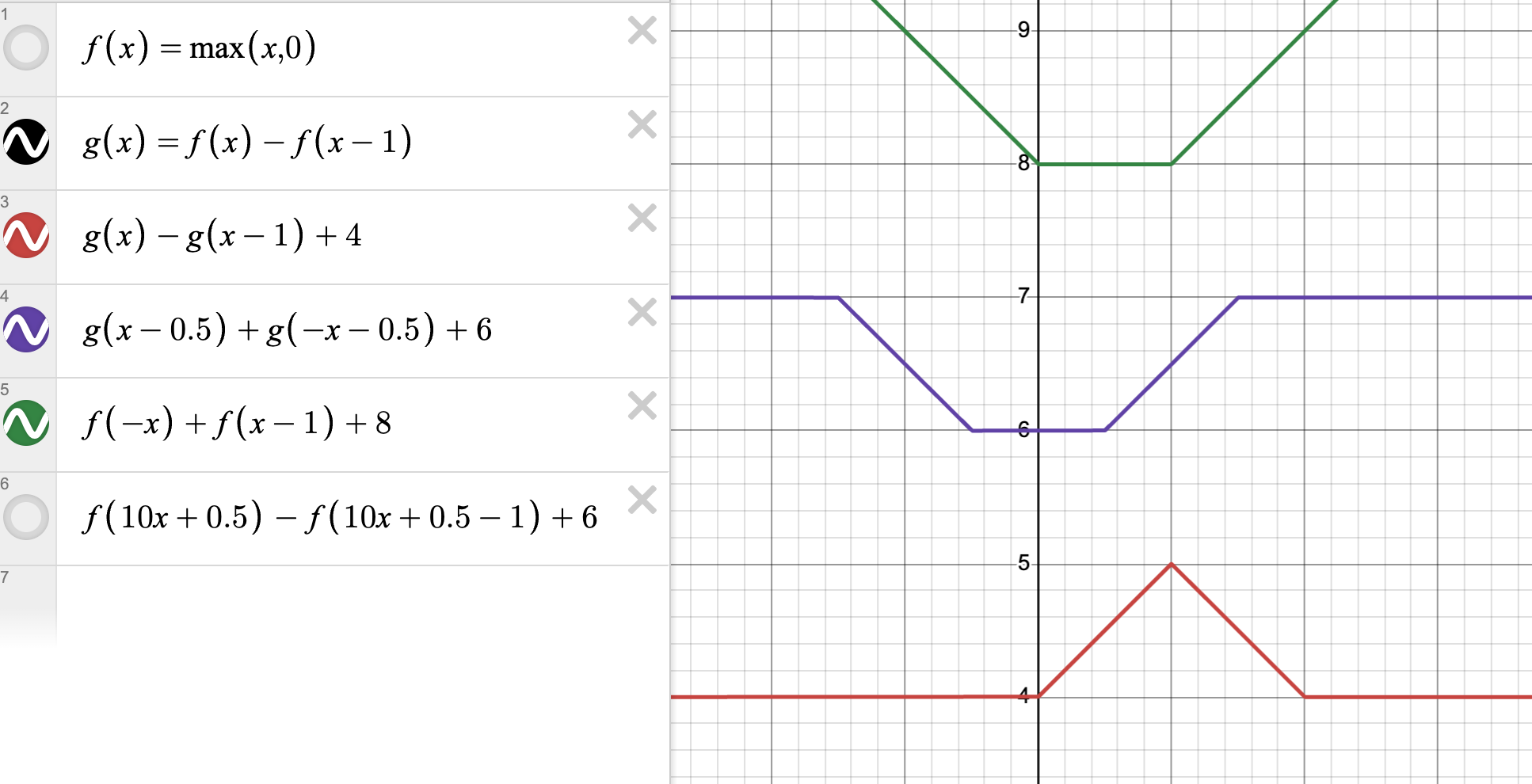
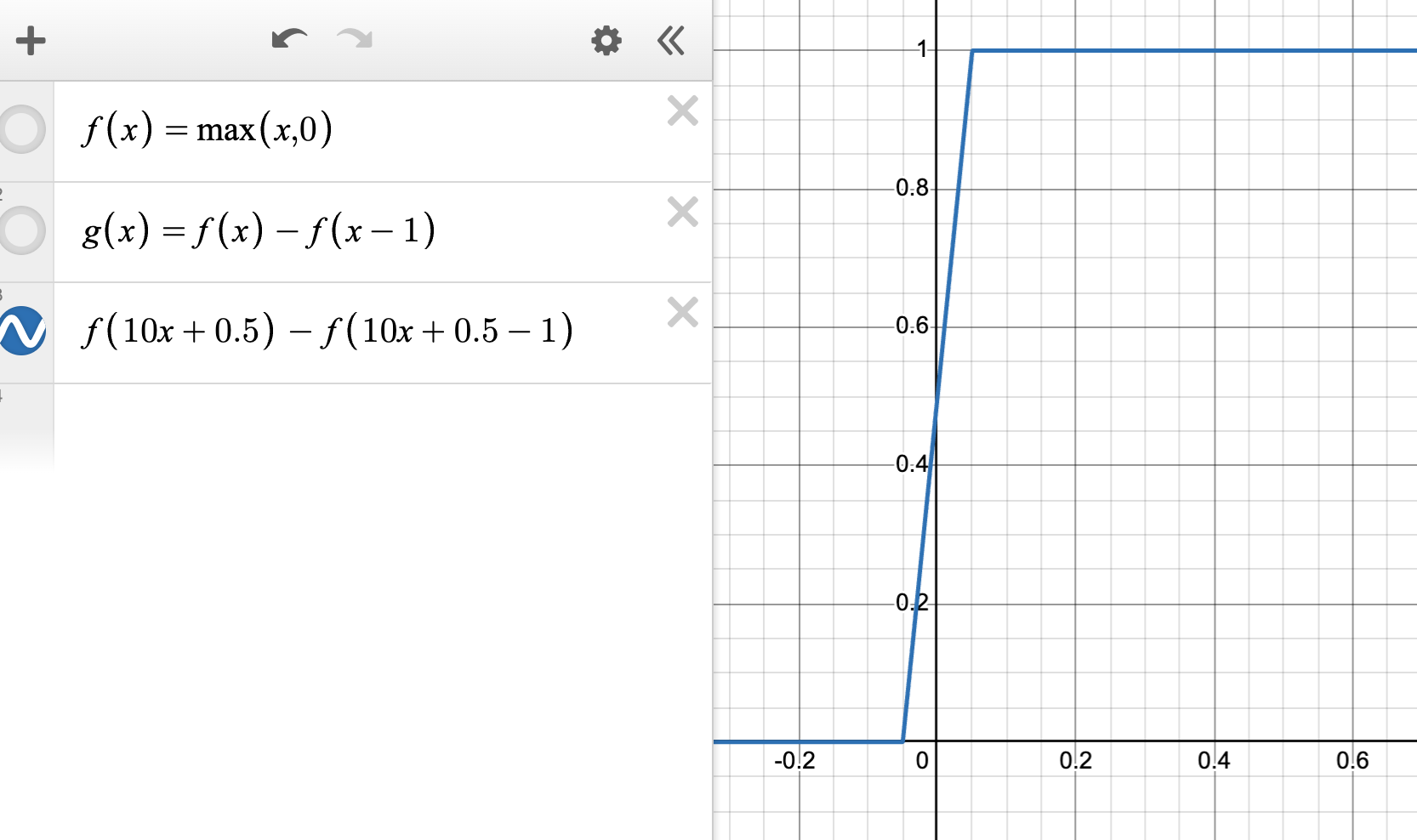
We can also increase the slope inside the clip to create an approximation to the discontinuous function .
To create crazier shapes, check out this Jane Street blog where they used ReLU networks to create their logo.
LeakyReLU and the zero gradient problem
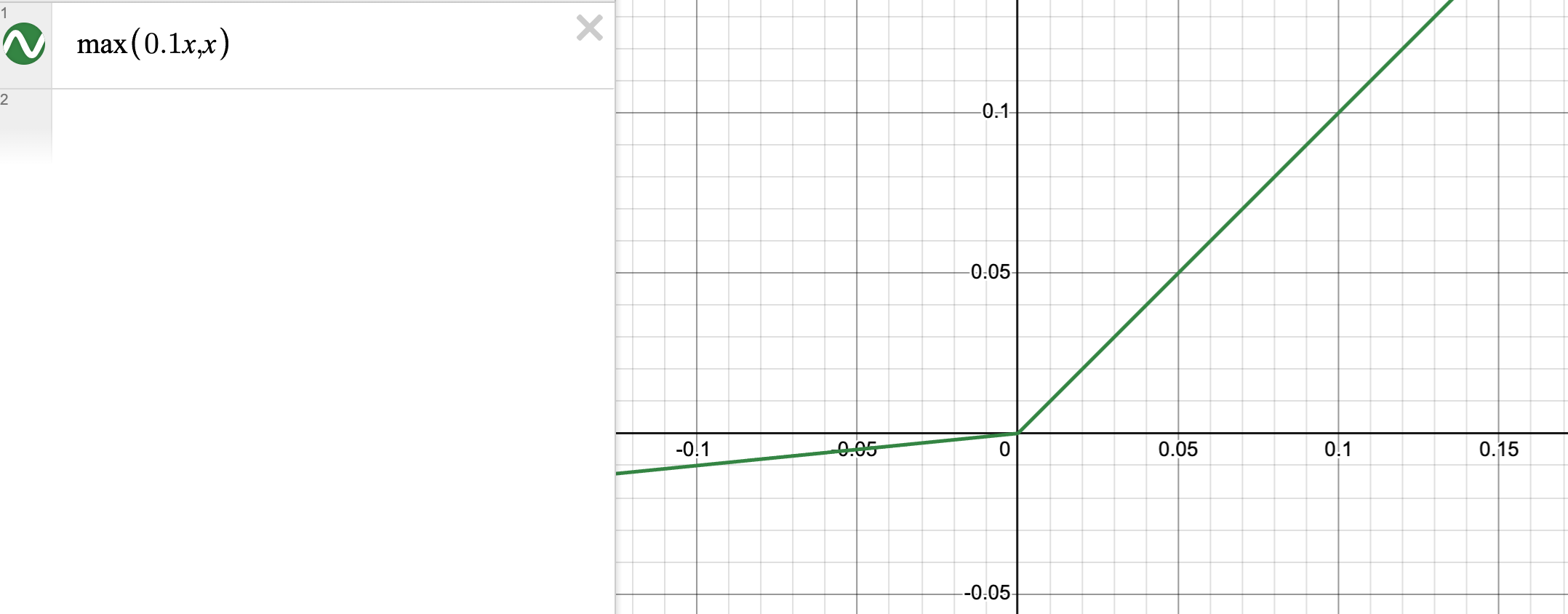
If our linear layer is a Gaussian distribution with zero mean, then about half of the elements in the output will be negative. Because of ReLU, the weights responsible for negative outputs will receive zero gradients in the backward pass. To alleviate this problem, we can use:
This way, all weights will get nonzero gradients.